Acquisition functions as expected utility
Suppose we have an expensive and possibly-noisy black-box function \(f\), i.e., we can query at a location \(x\) and get \(y = f(x)\) but we do not have additional information about \(f\).
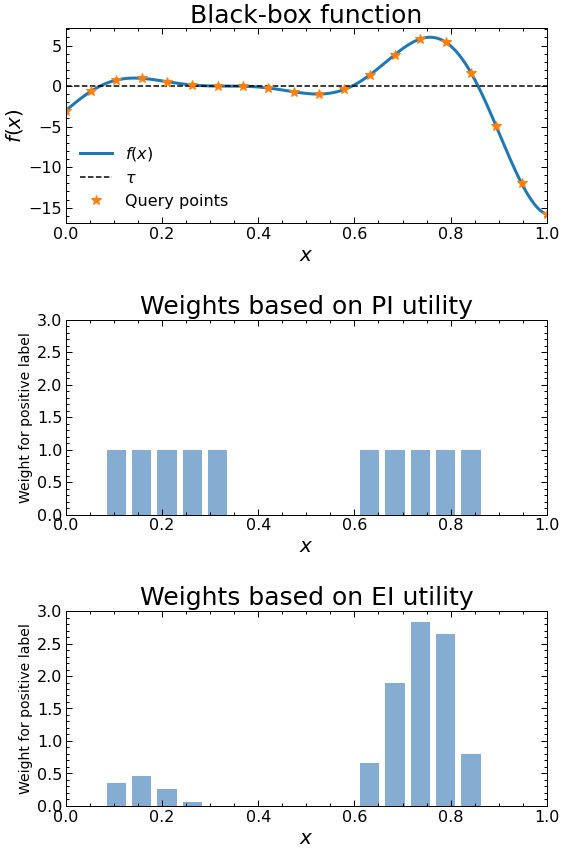
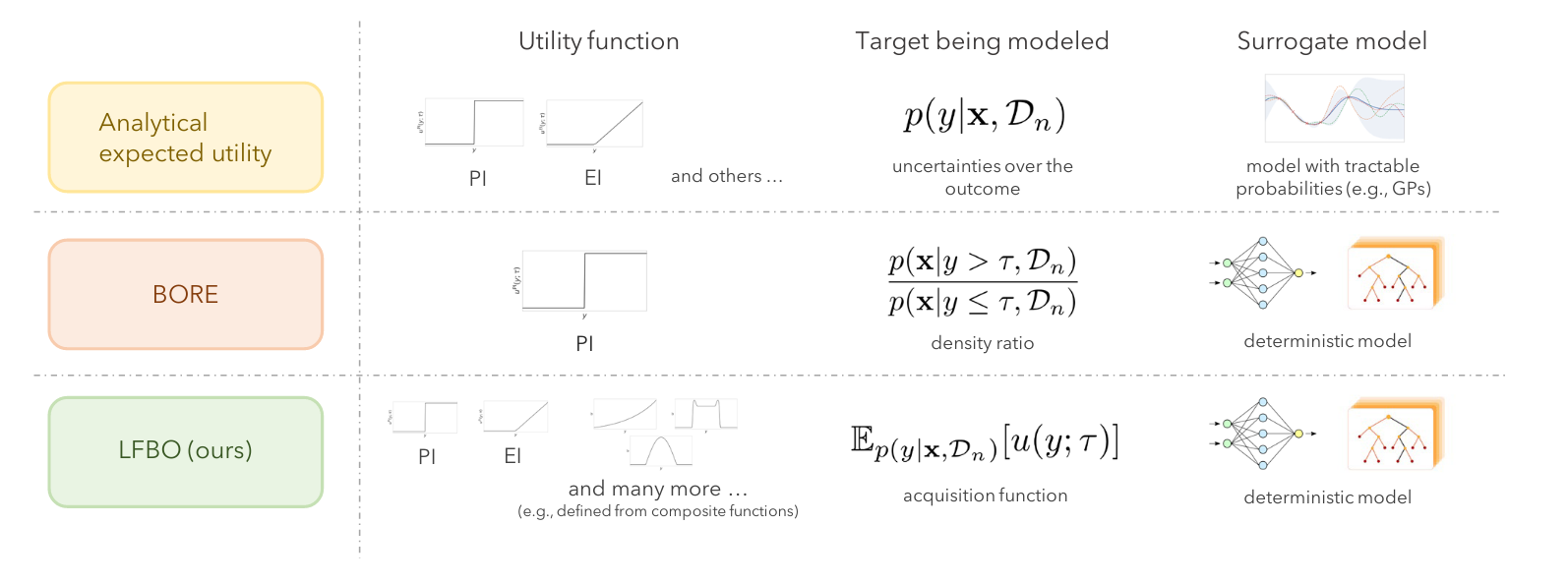
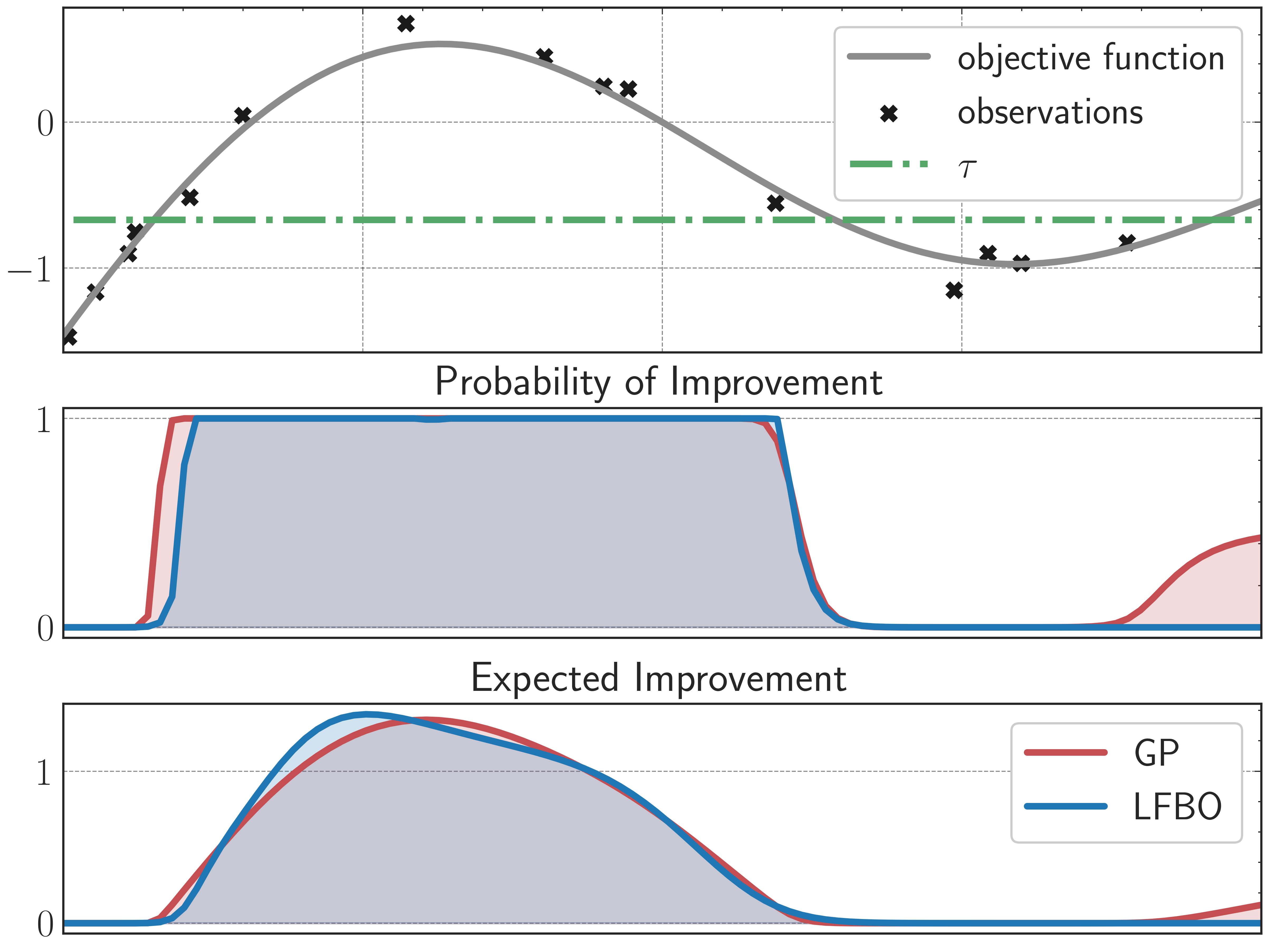
In Bayesian Optimization, one aims to maximize a black-box function \(f\) from a series of queries. Denote the \(n\) queries we get as \(\mathcal{D}_n = \{(x_1, y_1), \ldots, (x_n, y_n)\}\). Often, a surrogate model \(p(y | x, \mathcal{D}_n)\) is used to decide where we query next (i.e., \(x_{n+1}\)). This is done by finding the argmax of an acquisition function in the form of the expectation of some utility function: $$ \mathbb{E}_{y \sim p(y | x, \mathcal{D}_n)}[u(y; \tau)] = \int u(y; \tau) p(y | x, \mathcal{D}_n) \mathrm{d} y $$ where \(\tau\) can be treated as a threshold. Common acquisition functions include:
- Probability of Improvement (PI): \(u^{\mathrm{PI}}(y; \tau) := \mathbb{I}(y - \tau, 0)\), where \(\mathbb{I}\) is the binary indicator function. This indicates whether \(y\) is above or below the threshold \(\tau\) or not.
- Expected Improvement (EI): \(u^{\mathrm{EI}}(y; \tau) := \max(y - \tau, 0)\). This indicates by how much \(y\) is above the threshold \(\tau\) (if it is below, then 0 is returned).
When the surrogate model is a GP, the expectations in PI and EI have analytical forms; however, this is not necessarily true for other utility functions.